Assessing Annotator Identity Sensitivity via Item Response Theory: A Case Study in a Hate Speech Corpus
Abstract
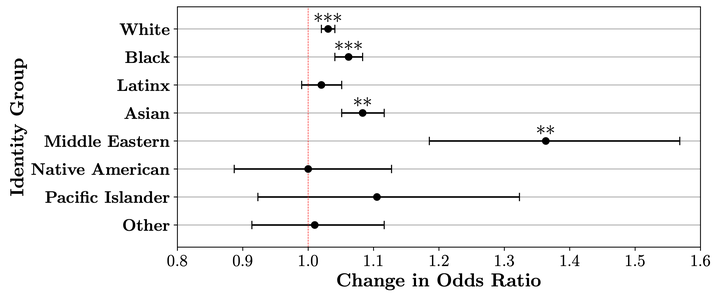
Annotators, by labeling data samples, play an essential role in the production of machine learning datasets. Their role is increasingly prevalent for more complex tasks such as hate speech or disinformation classification, where labels may be particularly subjective, as evidenced by low inter-annotator agreement statistics. Annotators may exhibit observable differences in their labeling patterns when grouped by their self-reported demographic identities, such as race, gender, etc. We frame these patterns as annotator identity sensitivities, referring to an annotator’s increased likelihood of assigning a particular label on a data sample, conditional on a self-reported identity group. We purposefully refrain from using the term annotator bias, which we argue is problematic terminology in such subjective scenarios. Since annotator identity sensitivities can play a role in the patterns learned by machine learning algorithms, quantifying and characterizing them is of paramount importance for fairness and accountability in machine learning. In this work, we utilize item response theory (IRT), a methodological approach developed for measurement theory, to quantify annotator identity sensitivity. IRT models can be constructed to incorporate diverse factors that influence a label on a specific data sample, such as the data sample itself, the annotator, and the labeling instrument’s wording and response options. An IRT model captures the contributions of these facets to the label via a latent-variable probabilistic model, thereby allowing the direct quantification of annotator sensitivity. As a case study, we examine a hate speech corpus containing over 50,000 social media comments from Reddit, YouTube, and Twitter, rated by 10,000 annotators on 10 components of hate speech (e.g., sentiment, respect, violence, dehumanization, etc.). We leverage three different IRT techniques which are complementary in that they quantify sensitivity from different perspectives: separated measurements, annotator-level interactions, and group-level interactions. We use these techniques to assess whether an annotator’s racial identity is associated with their ratings on comments that target different racial identities. We find that, after controlling for the estimated hatefulness of social media comments, annotators tended to be more sensitive when rating comments targeting a group they identify with. Specifically, annotators were more likely to rate comments targeting their own racial identity as possessing elements of hate speech. Our results identify a correspondence between annotator identity and the target identity of hate speech comments, and provide a set of tools that can assess annotator identity sensitivity in machine learning datasets at large.